PostgreSQL 테이블 Bloat, Bloating(부풀림) 현상 해결(Vacuum)
※ 업무하면서 습득한 내용들을 정리해 놓은 포스팅입니다 :P 추가로 궁금하신 점은 댓글로 남겨주시고 필요한 자료 있으면 요청주세요! 잘못된 내용이 있으면 고쳐주시면 감사하겠습니다. 자료 퍼가실 때는 출처 남겨주세요!
ο 목차
※ 코드 보는 방법 참고
ㅇ 달러 기호($)가 있는 경우 -> 리눅스 터미널에서 CLI 명령어 입력
ㅇ "=>" 기호가 있는 경우 -> psql 쉘에서 명령어 입력
서비스 구축에 급급해서 PostgreSQL을 적절히 튜닝하지 않고 사용하다 보면 높은 확률로 실제 데이터 크기보다 데이터베이스 크기가 커지는 현상을 경험하게 됩니다. (팽창, bloating 현상)
이번 포스팅에서는 도대체 이런 현상이 왜 발생하는 것이며, 어떻게 해결할 수 있을지에 대한 내용을 공유해보려고 합니다.
아래 내용 잘 따라와주세요 :P
1. 문제 원인
문제를 이해하기 위해서는 MVCC, Table Bloat, Vaccum 아래의 3가지 개념에 대한 이해 필요
1) 개념 이해
(1) MVCC(다중 버전 동시성 제어)
- PostgreSQL에서 여러 사용자에 대한 동시 트랜잭션을 관리하는 기법
- UPDATE나 DELETE 작업 발생시 기존 자료와 변경된 자료를 지우지 않고 해당 테이블에 모두 저장
- 접근한 사용자들에 대해 접근 시점의 snapshot을 제공하여 동시성 관리
| 장점 | 단점 | |
| MVCC 기법 (다중 버전 동시성 제어) |
다른 RDBMS 보다 빠른 속도 사용자간 데이터 간섭 및 영향도 감소 |
실제로 사용되지 않는 데이터 증가 데이터 버전의 충돌 가능성 |
※ 다중 버전 동시성 제어를 위해 만들어졌지만 실제로 어플리케이션 단에서 사용되지 않는 데이터 행을 dead tuples라고 함.
(2) Table Bloat(테이블 부풀림, 팽창) 현상
- MVCC로 인해 만들어진 사용하지 않는 dead tuples가 계속 증가하여 실제 사용되는 데이터보다 데이터베이스 크기가 커지는 현상
(3) VACUUM
- MVCC로 인한 발생된 dead tuples를 정리하는 기능.
- 자료를 DELETE 하는 경우 MVCC로 인해 데이터가 사라지는 것이 아니라 dead tuples가 되어 데이터베이스에 남게됨.
- 이러한 dead tuples들은 vacuum 기능을 사용해서 정리한 후 다시 사용 가능한 데이터 공간(free space)으로 돌려 줄 필요가 있음.
2. 해결 방법 - vacuum 작업
CASE 1) 수동으로 vacuum 작업 해주기
※ 수동 vacuum 작업 전 주의 사항
▶ 수동 vacuum은 자동 vacuum과 달리 시스템 자원 사용 우선순위가 높음.
▶ 큰 테이블의 dead tuples를 수동 vacuum으로 처리하게 된다면 데이터베이스 시스템 자원이 부족하여 다른 작업에 영향을 줄 수 있으므로 시스템 영향도를 고려하여 테이블별 작업 진행 필요.
▶ 특별한 이유가 없다면 vacuum full (수동 전체 테이블 vacuum 작업) 작업은 권고하지 않음. (시스템 부하 발생)
(1) dead tuples 개수 확인(데이터베이스 소유자 계정으로 접속)
=> select relname,n_dead_tup from pg_stat_user_tables;- 각 테이블의 dead tuples 개수를 출력하는 명령어
- 예시)

(2) dead tuples가 많은 테이블에 대해서 vacuum 작업
=> vacuum 테이블이름;CASE 2) 자동으로 vacuum 작업 해주기(사용 권고)
(1) autovacuum 설정 확인
=> select name,setting,short_desc from pg_settings where name like 'autovacuum%';- 현재 설정 확인 후 아래 내용 참고하여 데이터베이스 환경에 맞게 autovacuum 설정 수정
(2) autovacuum 설정하기
ㅇ postgresql.conf 파일 위치 확인
$ psql -U postgres -c 'show config_file'
ㅇ postgresql.conf 파일에서 아래 항목 찾아서 적절한 값으로 수정
| 항목 | 설명 |
| autovacuum | autovacuum 백그라운드 프로세스 활성화 여부 선택 |
| autovacuum_analyze_scale_factor | autovacuum analyze를 트리거하는데 필요한 dead tuples의 수를 각 테이블 크기의 n%로 지정하여 실행하기 위한 항목 |
| autovacuum_analyze_threshold | 한 테이블에서 analyze를 트리거하는데 필요한 dead tuples의 최소 수를 지정 |
| autovacuum_freeze_max_age | 한 테이블 내에서 트랜잭션 ID 랩어라운드를 방지하기 위해 autovacuum을 시작하도록 강제하는 테이블 age 지정 |
| autovacuum_max_workers | 동시에 실행가능한 autovacuum 서브 프로세스 개수(autovacuum 실행 프로그램(launcher) 제외) |
| autovacuum_multixact_freeze_max_age | 한 테이블 내에서 multiact ID 랩어라운드를 방지하기 위해 autovacuum을 시작하도록 강제하는 테이블 age 지정 |
| autovacuum_naptime | autovacuum 프로세스 실행 간격 |
| autovacuum_vacuum_cost_delay | autovacuum 작업에 사용될 비용 지연 값 지정. (비용 지연 : autovacuum cost limit가 초과되는 경우 autovacuum 프로세스를 일시 중지하는 시간) |
| autovacuum_vacuum_cost_limit | autovacuum이 수행하는 작업양을 특정 cost로 제한 ※ cost_limit > 각 autovacuum worker에서 수행하는 작업량의 합 |
| autovacuum_vacuum_scale_factor | autovacuum vacuum 프로세스를 트리거하는데 필요한 dead tuples의 수를 각 테이블 크기의 n%로 지정하여 실행하기 위한 항목 |
| autovacuum_vacuum_threshold | 한 테이블에서 vacuum 프로세스를 트리거하는데 필요한 dead tuples의 최소 수를 지정 |
| autovacuum_work_mem | 작업 메모리가 지정되는 경우 설정된 메모리를 이용하여 작업하고, 해당 값이 -1인 경우 maintenance_work_mem를 공유하여 작업 진행 |
ㅇ autovacuum 설정값 설정시 고려 사항
▶ autovacuum max workers 설정시 고려 사항
: 큰 테이블(large table)에 대한 autovacuum 작업시 단일 테이블의 vacuum 작업을 수행하는데 autovacuum_max_workers에서 설정된 서브 프로세스를 모두 사용하는 경우, 다른 테이블의 dead tuples 정리 작업을 처리하지 못할 수 있음. (autovacuum의 한계)
: autovacuum worker 또한 시스템 자원을 소모하기 때문에 무조건 크게 설정하는 것이 아니라 서비스에 영향이 없을 정도의 worker 수로 설정. (일반적으로 cpu 코어 수의 1~2배 범위 안에서 지정)
▶ scale_factor 설정시 고려 사항
: 큰 테이블일 경우 scale_factor 값이 크면 autovacuum 프로세스가 한번에 처리해야 하는 dead tuples의 수가 많기 때문에 autovacuum 작업이 제대로 처리되지 못할 수 있음. 테이블의 크기를 고려하여 설정 필요.
(3) autovacuum 작업 모니터링
ㅇ 아래 명령어로 autovacuum 작업량 확인
=> select relname,n_live_tup, n_dead_tup,last_autovacuum from pg_stat_user_tables;- last_autovacuum 값을 참고하여 autovacuum이 정상적으로 동작하고 있는지 여부를 확인
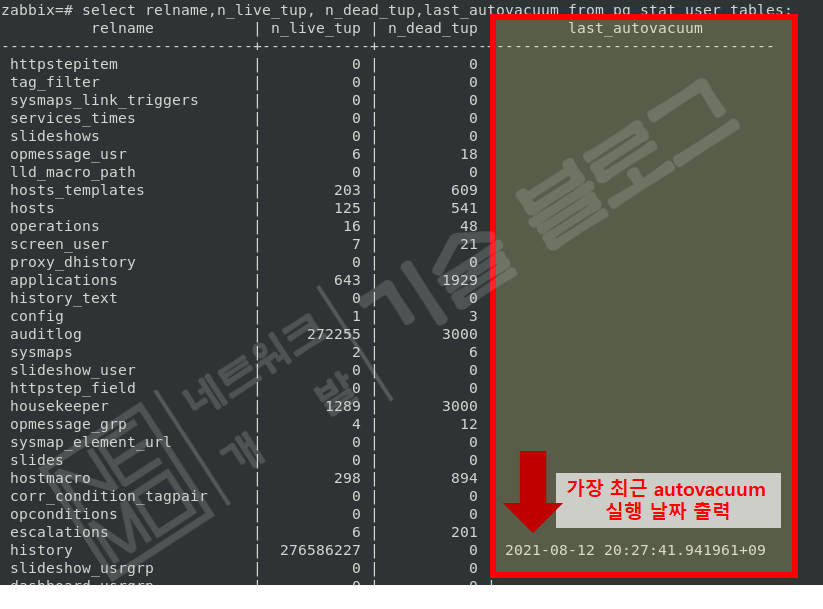
- n_dead_tup 값이 threshold 혹은 scale 값을 초과했음에도 autovacuum 이 실행되지 않는 경우, 적절한 빈도로 vacuum 작업이 일어날 수 있도록 설정값 조정 필요
** autovacuum을 실행시켰는데 dead tuples 수가 많은 경우(large) autovacuum threshold, scale 값을 초과 했음에도 데이터를 제거하지 못하는 경우가 있습니다.
이 경우에는 수동으로 vacuum을 해줘도 시간이 매우 오래 걸리거나 행(hang)이 걸릴 수 있기 때문에 차라리 데이터베이스 덤프 -> 데이터베이스 삭제 -> 데이터베이스 복원 과정을 통해 dead tuples를 정리하는게 효율적일 수 있습니다.
데이터베이스 환경에 따라 가장 적합한 방법을 선택하여 효율적으로 활용하시길 바랍니다.
※ 많은 도움이 되시길 바랍니다. 좋아요와 구독은 큰 힘이 됩니다 :P 감사합니다.